
The modern lakehouse architecture and Spark have become the go-to solutions for large-scale data processing, offering powerful capabilities for handling massive datasets. However, they are not always the best fit for every use case. For small to medium-sized datasets, the overhead of managing a Spark cluster can be unnecessary and costly.
In such scenarios, Azure Functions provide a lightweight, event-driven approach to processing smaller datasets. They enable efficient ingestion, transformation, and storage without the significant overhead of Spark. In this blog post, we’ll demonstrate how to use Azure Functions to process data and store it in Delta format, leveraging Pandas and delta-rs—making it a great option for near real-time, cost-effective data processing.
This is somewhat a comprehensive guide, so feel free to jump to the sections that interest you the most. We are going to assume you have some basic knowledge of deploying Azure Functions, Pandas, and Delta Lake. If you’re new to these technologies, we recommend checking out the official documentation in conjunction with this guide.
Table of Contents
1. Introduction
1.1 Why Use Azure Functions for Data Processing?
Cost & Performance Efficiency: Using Spark for small datasets can incur extra costs and reduce performance, making Azure Functions a much better option.
Scalability: Azure Functions automatically scale based on demand.
Simplicity: Works well for small to medium-sized datasets without the complexity of Spark.
1.2 Why Delta Format?
Unlike CSV or Parquet, Delta Lake provides:
- ACID Transactions: Ensures data consistency even in concurrent writes.
- Schema Evolution: Allows for automatic schema updates.
- Efficient Reads & Writes: Optimized for analytics workloads.
1.2.1 Why Not SQL?
I may hear some of you saying, “just use SQL instead” as our storage layer, and to be fair that is a valid choice. However, for our use case, Delta Lake provides a few key advantages over SQL in my opinion:
- Open Format: As an open-source project, Delta Lake ensures compatibility with a wide range of tools and platforms, reducing the risk of vendor lock-in.
- Reduced Maintenance: Delta Lake’s schema-on-read approach minimizes the need for upfront schema design, and its support for schema evolution simplifies handling changes in data structure.
- Cost Effectiveness: Delta Lake separates storage and compute resources, allowing for independent scaling. In contrast, SQL databases often couple storage and compute, which can lead to higher costs.
1.3 The Use Case
We will be fetching weather forecast data from the freely available **[7timer! API](https://www.7timer.info/doc.php)** for various products (e.g., astro, civil, civillight, meteo, two) and storing each table in Delta format in a data lake. We need to optimize the process for fast retrieval, processing, and storage of the data – whilst minimizing costs. This is where Azure Functions come in.
1.4 Architecture & Key Technologies
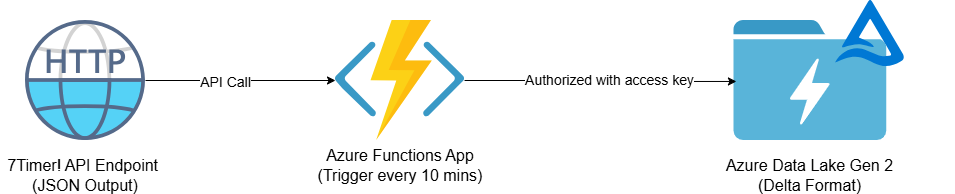
This solution is designed to efficiently process small to medium-sized datasets using a lightweight, event-driven approach. Instead of relying on a Spark cluster, Azure Functions orchestrate the entire ETL workflow in parallel, enabling near real-time data processing.
1.5 How It Works
Scheduled Execution – An Azure Function is triggered at a defined interval to fetch and process new data.
Parallel Processing – Data ingestion, transformation, and storage are executed concurrently.
Data Transformation – The raw API responses are structured into DataFrames.
Delta Lake Storage – The transformed data is stored in Delta format in a data lake.
1.6 Technology Stack & Deployment Strategy
This solution leverages Azure Function with Python Runtime for scheduled execution and parallel data processing, alongside Azure Data Lake Storage (ADLS) Gen2 for scalable and secure storage.
1.6.1. Key Components
- Azure Function (Python Runtime) – Orchestrates execution and parallel processing using:
- Pandas for data transformation.
- delta-rs for Delta Lake storage with ACID transactions and schema enforcement, without requiring Spark.
- ThreadPoolExecutor for faster API ingestion and processing.
- Azure Data Lake Storage (ADLS) Gen2 – Stores processed Delta files in a dedicated container (e.g., `data`).
1.6.2. Deployment Considerations
- Azure Function Hosting:
- Recommended plans: Flex Consumption (cost-effective, limited regions) or Premium Plan.
- Consumption plan is not supported for Python functions.
- Storage Strategy:
- The Function App will create an internal storage account for logging—do not use this for data storage.
- Deploy a separate ADLS Gen2 account for your Delta files.
By integrating these technologies, this solution ensures efficient, scalable, and near real-time data processing with minimal operational overhead.
1.7 Defining Dependencies
After deploying our Azure Function App, we need to define our requirements.txt file for our Python function. We will use the following libraries:
```txt
azure-functions
pandas
requests
deltalake
```
These libraries ensure that our Azure Function can fetch data, process it using Pandas, and store it efficiently in Delta format.
2. Implementation
After setting up our Azure Function App, we can begin writing the Python code to fetch, process, and store data. We’ll divide the implementation into manageable steps. Our code will collect data from various APIs, process it, and save it in Delta format in Azure Data Lake Storage (ADLS) every 10 minutes. Given the complexity, it’s essential to break it down into manageable parts. Here’s an outline of the steps we’ll follow:
- Define our imports
- Initialize our Azure Function app
- Define our configuration variables and API URLs
- Define our functions to fetch, transform, and store data.
- Define our timer trigger decorator to run the orchestrator function every 10 minutes.
Steps 1-3 are straightforward, so let’s start with those.
2.1. Initializing the Azure Function App & Configurations
```python
import logging
import requests
import os
import pandas as pd
from deltalake import write_deltalake
from datetime import datetime
import azure.functions as func
from concurrent.futures import ThreadPoolExecutor, as_completed
### Initialize Azure Function app ###
app = func.FunctionApp()
### Define configuration variables and API URLs ###
AZURE_STORAGE_ACCOUNT_NAME = os.getenv("AZURE_STORAGE_ACCOUNT_NAME")
AZURE_STORAGE_ACCOUNT_KEY = os.getenv("AZURE_STORAGE_ACCOUNT_KEY")
CONTAINER_NAME = "data" # Rename this to your ADLS container name
API_URLS = {
"astro": "http://www.7timer.info/bin/api.pl?lon=113.17&lat=23.09&product=astro&output=json",
"civil": "http://www.7timer.info/bin/api.pl?lon=113.17&lat=23.09&product=civil&output=json",
"civillight": "http://www.7timer.info/bin/api.pl?lon=113.17&lat=23.09&product=civillight&output=json",
"meteo": "http://www.7timer.info/bin/api.pl?lon=113.17&lat=23.09&product=meteo&output=json",
"two": "http://www.7timer.info/bin/api.pl?lon=113.17&lat=23.09&product=two&output=json",
}
```
After importing the required modules, we proceed with the following steps:
1. Initialize the Azure Function App
- We use call the `func.FunctionApp()` class to initialize the function app.
- This object will be used to define our timer trigger later on.
2. Define Configuration Variables
- Storage Account Credentials
- `AZURE_STORAGE_ACCOUNT_NAME`: The name of the Azure Data Lake Storage (ADLS) account.
- `AZURE_STORAGE_ACCOUNT_KEY`: The access key for authentication.
- **ADLS Container Name**
- `CONTAINER_NAME`: Specifies the ADLS container where processed data will be stored.
3. Define API Endpoints
- The `API_URLS` dictionary containing product names and corresponding URLs for 7timer! APIs.
2.11. Managing Secrets & Security Considerations
- Environment Variables for Secrets
- Sensitive credentials (`AZURE_STORAGE_ACCOUNT_NAME` and `AZURE_STORAGE_ACCOUNT_KEY`) are stored as environment variables, which can be configured in the Azure Function App settings within the Azure Portal.
- This approach is simple and prevents hardcoding secrets in the script.
- Recommended Security Best Practices
- Azure Key Vault: In a production environment, it’s probably better to use Azure Key Vault for securely storing and managing secrets. There is a Python SDK available for interacting with Key Vault, which is beyond the scope of this post.
- Principal of Least Privilege: Instead of using an access key, which grants blanket privileges, consider more restrictive alternatives like Shared Access Signature (SAS) tokens. Again, this is a more advanced topic that we won’t cover here.
2.2. Timer Trigger & Orchestrator Functions
To begin, we require two essential components to create an event-based function in an Azure Functions App: a trigger decorator and an orchestrator function. The trigger decorator defines the type of trigger that will activate the function, while the orchestrator function serves as the main function that coordinates the entire workflow.
```python
@app.trigger_type(
arg_name="myTrigger",
**trigger_params
)
def orchestration_function(myTrigger):
### Your code here ###
```
For our use case we’ll use the timer trigger decorator `@app.timer_trigger` and name our orchestrator function `app_trigger_process_api_data()`. This is where the magic happens—it automates the process of fetching, processing, and storing data from multiple APIs on a fixed schedule. Let’s quickly examine the code before diving into the details, it looks intimidating at first glance, but we’ll break it down step by step:
```python
@app.timer_trigger(
schedule="0 */10 * * * *",
arg_name="appTimer",
run_on_startup=False,
use_monitor=False,
)
def app_trigger_process_api_data(appTimer: func.TimerRequest) -> None:
logging.info("🔄 Python timer trigger function started.")
if appTimer.past_due:
logging.warning("⚠️ The timer is past due!")
try:
with ThreadPoolExecutor() as executor:
futures = {
executor.submit(fetch_and_store_data, name, url): name for name, url in API_URLS.items()
}
# Logging when threads complete
for future in as_completed(futures):
try:
future.result() # Ensures exceptions are raised
logging.info(f"✅ Completed processing for {futures[future]}")
except Exception as e:
logging.error(f"❌ {futures[future]} failed with error: {e}")
except Exception as e:
logging.error(f"❌ An error occurred in multi-threading: {e}")
logging.info("✅ Python timer trigger function completed.")
```
2.21. Understanding the Timer Trigger
Let’s start with our trigger. Our function is designed to run on a timer trigger, meaning it executes our orchestrator function automatically on a schedule. Azure Functions offers various triggers, such as HTTP triggers, Blob triggers, and Event Grid triggers (see references below), but in this case, we specify a timer trigger using the `@app.timer_trigger()` decorator. Remember, `app` is the `func.FunctionApp()` object we initialized at the beginning of our script.
```python
@app.timer_trigger(
schedule="0 */10 * * * *",
arg_name="appTimer",
run_on_startup=False,
use_monitor=False,
)
```
The key parameters to note for this particular trigger type are `schedule` and `arg_name`. The `schedule` parameter employs a cron expression to dictate the frequency of function execution. In this case, the expression `”0 */10 * * * *”` guarantees that the function runs every 10th minute, throughout the day (for instance, at 12:00, 12:10, 12:20, and so on).
The `arg_name` parameter defines the argument name (`appTimer` in our case) that will be passed to the orchestrator function. Other parameters, while less critical to our discussion, control startup behavior and monitoring settings.
2.22. What Happens Inside the Orchestrator Function?
```python
def app_trigger_process_api_data(appTimer: func.TimerRequest) -> None:
logging.info("🔄 Python timer trigger function started.")
if appTimer.past_due:
logging.warning("⚠️ The timer is past due!")
try:
with ThreadPoolExecutor() as executor:
futures = {
executor.submit(fetch_and_store_data, name, url): name for name, url in API_URLS.items()
}
# Logging when threads complete
for future in as_completed(futures):
try:
future.result() # Ensures exceptions are raised
logging.info(f"✅ Completed processing for {futures[future]}")
except Exception as e:
logging.error(f"❌ {futures[future]} failed with error: {e}")
except Exception as e:
logging.error(f"❌ An error occurred in multi-threading: {e}")
logging.info("✅ Python timer trigger function completed.")
```
Upon first looks, the orchestrator function `app_trigger_process_api_data()` appears to be quite complex. However, it’s relatively straightforward once we break it down. Here’s a summary of the key steps:
1. Logging the Start of Execution
- The function logs a message when execution begins.
2. Handling Overdue Executions
- If the timer is late (`appTimer.past_due`), it logs a warning.
3. Fetching & Processing Data Concurrently **(CRITICAL STEP)**
- A `ThreadPoolExecutor` is used to fetch data from multiple APIs in parallel.
- The `executor.submit()` method is called for each API URL, passing the `fetch_and_store_data` function and the API name and URL from the `API_URLS` dictionary.
4. Error Handling & Logging
- The function iterates over completed threads (`as_completed(futures)`) to log success or capture errors.
- Any failures are logged with specific API names for easier debugging.
5. Completion Log
- Once all tasks are processed, a final log confirms execution is complete.
As you can see, most of this function is just logging and error handling. The actual processing occurs through the parallel execution of the `fetch_and_store_data()` function, which we will define next.
2.3. Extract, Transform, Load (ETL) Functions
Now we have the hard part out of the way, let’s focus on the data processing. The `fetch_and_store_data()` function is our ETL function that calls 3 other functions to extract, transform, and load the data:
- `fetch_api_data()` to fetch data from the API (extract)
- `transform_api_data()` to transform the fetched data into a Pandas DataFrame (transform)
- `store_data_in_adls()` to store the transformed data in ADLS in Delta format (load)
```python
def fetch_and_store_data(api_name, api_url):
"""Fetch, transform, and store data for a given API."""
logging.info(f"🔄 Starting processing for {api_name}...")
data = fetch_api_data(api_url)
if data:
df = transform_api_data(api_name, data)
store_data_in_adls(api_name, df)
logging.info(f"✅ Finished processing {api_name}.")
```
The rest of this function is just logging and a conditional check to ensure that the data is not empty before proceeding with the transformation and storage steps.
We will define the individual ETL functions in the following sections.
2.3.1. Extract – Fetching Data from the API
This part represents the extract phase of our ETL process – in our case it’s just your bread-and-butter JSON API request handler.
Your extraction logic may vary significantly based on your data source, so there’s no need to fully understand the entire process here. You can proceed to the next section without a loss of understanding of the critical components. However, if you’re curious, here’s a brief explanation of its purpose:
- Retrieves data from the specified API URL
- Verifies for any errors
- Returns the JSON response
- Checks to ensure that the data is not empty
- Confirms the presence of the expected `dataseries` key specific to the API
- Logs the error if an error occurs during the request
- Returns `None` if an error occurs
```python
def fetch_api_data(api_url):
"""Fetch JSON data from the given API URL."""
try:
response = requests.get(api_url)
response.raise_for_status()
data = response.json()
if not data or "dataseries" not in data:
logging.warning(f"⚠️ API {api_url} returned empty or invalid response.")
return None
return data
except requests.exceptions.RequestException as e:
logging.error(f"❌ Failed to fetch data from API: {api_url} | Error: {e}")
return None
```
2.3.2. Transform – Manipulate Data with Pandas
This section outlines the transform phase of our ETL process.
Again, the internal logic here will likely not be relevant to you – the key takeaway is that we’re using Pandas, rather than Spark, to manipulate the data in memory before storing it in ADLS. Feel free to skim over this section, but for the curious amongst you, the function:
- Utilizes `pd.json_normalize()` to flatten the JSON response into a DataFrame
- Adds a timestamp column to track ingestion time
- Verifies whether the DataFrame is empty
- If the DataFrame is empty, logs a warning and returns `None`
- In the event of an error during processing, logs the error and returns `None`
```python
def transform_api_data(api_name, data):
"""Transform JSON response into a pandas DataFrame."""
try:
df = pd.json_normalize(data, record_path=["dataseries"], meta=["product", "init"])
df["ingestion_timestamp_utc"] = datetime.utcnow()
if df.empty:
logging.warning(f"⚠️ No records found in {api_name}, skipping storage.")
return None
return df
except Exception as e:
logging.error(f"❌ Failed to process data for {api_name}: {e}")
return None
```
2.3.3. Load – Storing Data in ADLS in Delta Format
Finally, we have the load phase of our ETL process. This part of our code is the critical step where we store the transformed data in ADLS in Delta format, so take some time to understand what’s happening here. We use the `write_deltalake()` function from the `delta-rs` library to write the DataFrame to Delta format directly in ADLS.
```python
def store_data_in_adls(api_name, df):
"""Write the DataFrame to Delta format in ADLS."""
if df is None or df.empty:
logging.warning(f"⚠️ No data to store for {api_name}. Skipping write.")
return
adls_path = f"abfss://{CONTAINER_NAME}@{AZURE_STORAGE_ACCOUNT_NAME}.dfs.core.windows.net/{api_name}"
storage_options = {
"AZURE_STORAGE_ACCOUNT_NAME": AZURE_STORAGE_ACCOUNT_NAME,
"AZURE_STORAGE_ACCOUNT_KEY": AZURE_STORAGE_ACCOUNT_KEY,
}
try:
logging.info(f"📤 Writing data for {api_name} to {adls_path} (overwrite mode)...")
write_deltalake(
adls_path,
df,
mode="overwrite",
schema_mode="merge",
storage_options=storage_options,
)
logging.info(f"✅ Successfully written {api_name} data to ADLS.")
except Exception as e:
logging.error(f"❌ Failed to store data for {api_name}: {e}")
```
In a nutshell, this function performs the following tasks:
- Checks if the DataFrame is empty or `None` and logs a warning if so.
- Constructs the ADLS path using `CONTAINER_NAME`, `AZURE_STORAGE_ACCOUNT_NAME`, and `api_name`.
- Prepares the `storage_options` dictionary with the Azure Storage account name and key for authentication.
- Writes the DataFrame to Delta format in ADLS using the `write_deltalake()` function.
- Uses `mode=”overwrite”` to replace the data in every run.
- Uses `schema_mode=”merge”` to allow for schema evolution.
- Logs any errors that occur during storage.
We now have an ACID-compliant, versioned, and schema-enforced storage solution for our processed data. With this, we’ve completed the ETL process for our Azure Function app. The final step is to combine all the components into a single script.
2.4. Complete Code
Now that we have all the pieces, let’s stitch them all together to complete our Azure Function app code. Here’s the complete script:
```python
import logging
import requests
import os
import pandas as pd
from deltalake import write_deltalake
from datetime import datetime
import azure.functions as func
from concurrent.futures import ThreadPoolExecutor, as_completed
### Initialize Azure Function app ###
app = func.FunctionApp()
### Define configuration variables and API URLs ###
AZURE_STORAGE_ACCOUNT_NAME = os.getenv("AZURE_STORAGE_ACCOUNT_NAME")
AZURE_STORAGE_ACCOUNT_KEY = os.getenv("AZURE_STORAGE_ACCOUNT_KEY")
CONTAINER_NAME = "data" # Rename this to your ADLS file system name
API_URLS = {
"astro": "http://www.7timer.info/bin/api.pl?lon=113.17&lat=23.09&product=astro&output=json",
"civil": "http://www.7timer.info/bin/api.pl?lon=113.17&lat=23.09&product=civil&output=json",
"civillight": "http://www.7timer.info/bin/api.pl?lon=113.17&lat=23.09&product=civillight&output=json",
"meteo": "http://www.7timer.info/bin/api.pl?lon=113.17&lat=23.09&product=meteo&output=json",
"two": "http://www.7timer.info/bin/api.pl?lon=113.17&lat=23.09&product=two&output=json",
}
### Define functions to fetch, transform, and store the data ###
def fetch_api_data(api_url):
"""Fetch JSON data from the given API URL."""
try:
response = requests.get(api_url)
response.raise_for_status()
data = response.json()
if not data or "dataseries" not in data:
logging.warning(f"⚠️ API {api_url} returned empty or invalid response.")
return None
return data
except requests.exceptions.RequestException as e:
logging.error(f"❌ Failed to fetch data from API: {api_url} | Error: {e}")
return None
def transform_api_data(api_name, data):
"""Transform JSON response into a pandas DataFrame."""
try:
df = pd.json_normalize(data, record_path=["dataseries"], meta=["product", "init"])
df["ingestion_timestamp_utc"] = datetime.utcnow()
if df.empty:
logging.warning(f"⚠️ No records found in {api_name}, skipping storage.")
return None
return df
except Exception as e:
logging.error(f"❌ Failed to process data for {api_name}: {e}")
return None
def store_data_in_adls(api_name, df):
"""Write the DataFrame to Delta format in ADLS."""
if df is None or df.empty:
logging.warning(f"⚠️ No data to store for {api_name}. Skipping write.")
return
adls_path = f"abfss://{CONTAINER_NAME}@{AZURE_STORAGE_ACCOUNT_NAME}.dfs.core.windows.net/{api_name}"
storage_options = {
"AZURE_STORAGE_ACCOUNT_NAME": AZURE_STORAGE_ACCOUNT_NAME,
"AZURE_STORAGE_ACCOUNT_KEY": AZURE_STORAGE_ACCOUNT_KEY,
}
try:
logging.info(f"📤 Writing data for {api_name} to {adls_path} (overwrite mode)...")
write_deltalake(
adls_path,
df,
mode="overwrite",
schema_mode="merge",
storage_options=storage_options,
)
logging.info(f"✅ Successfully written {api_name} data to ADLS.")
except Exception as e:
logging.error(f"❌ Failed to store data for {api_name}: {e}")
def fetch_and_store_data(api_name, api_url):
"""Fetch, transform, and store data for a given API."""
logging.info(f"🔄 Starting processing for {api_name}...")
data = fetch_api_data(api_url)
if data:
df = transform_api_data(api_name, data)
store_data_in_adls(api_name, df)
logging.info(f"✅ Finished processing {api_name}.")
### Define the timer trigger decorator & orchestrator function to run every 10th minute ###
@app.timer_trigger(
schedule="0 */10 * * * *",
arg_name="appTimer",
run_on_startup=False,
use_monitor=False,
)
def app_trigger_process_api_data(appTimer: func.TimerRequest) -> None:
"""Orchestrator function to fetch, process, and store data."""
logging.info("🔄 Python timer trigger function started.")
if appTimer.past_due:
logging.warning("⚠️ The timer is past due!")
try:
with ThreadPoolExecutor() as executor:
futures = {
executor.submit(fetch_and_store_data, name, url): name for name, url in API_URLS.items()
}
# Logging when threads complete
for future in as_completed(futures):
try:
future.result() # Ensures exceptions are raised
logging.info(f"✅ Completed processing for {futures[future]}")
except Exception as e:
logging.error(f"❌ {futures[future]} failed with error: {e}")
except Exception as e:
logging.error(f"❌ An error occurred in multi-threading: {e}")
logging.info("✅ Python timer trigger function completed.")
```
---
3. Summary
In this post, we demonstrated how Azure Functions can efficiently process small to medium-sized datasets without the overhead of Spark, making it a cost-effective and scalable solution, particularly for near real-time data processing.
What We Covered:
- Event-Driven Data Processing – We used an Azure timer trigger to schedule automated data ingestion and processing.
- Parallel Execution – By leveraging `ThreadPoolExecutor`, we optimized performance by processing multiple API requests concurrently.
- Lightweight ETL with Pandas – Instead of Spark, we used **Pandas** for data transformation, making it ideal for smaller workloads.
- Delta Format for Reliable Storage – We stored the processed data in Azure Data Lake Storage (ADLS) Gen2 using Delta format with delta-rs, ensuring ACID transactions, schema enforcement, and versioning.
- Simplified Infrastructure – This solution eliminates the need for a Spark cluster, reducing costs and complexity while maintaining efficiency.
This approach provides a scalable, event-driven architecture for real-time data processing without unnecessary infrastructure overhead.
I hope you’re all having a fantastic day! Happy coding, and most importantly, don’t forget to take care of yourselves. Stay hydrated and remember to take breaks—it’s easy to overlook this in today’s hustle culture. You deserve it. 😊
Reference Documentation
Here are key resources for Azure Functions, their triggers, and the delta-rs library:
- [Azure Functions Documentation](https://learn.microsoft.com/en-us/azure/azure-functions/)
- Comprehensive guide to building event-driven, serverless applications with Azure Functions.
- [Azure Functions Triggers and Bindings](https://learn.microsoft.com/en-us/azure/azure-functions/functions-triggers-bindings)
- Detailed information on how to use triggers and bindings to connect your functions to other services.
- [Pandas Documentation](https://pandas.pydata.org/docs/)
- Official documentation for the Pandas library, providing detailed information on data manipulation and analysis.
- [delta-rs Documentation](https://delta-io.github.io/delta-rs/)
- Official documentation for the delta-rs library, providing native Rust and Python APIs for Delta Lake operations.
- [7timer! API Documentation](https://www.7timer.info/doc.php)
- Official documentation for the 7timer! API, which provides weather forecast data for various locations.
These resources should help you effectively implement Azure Functions and work with Delta Lake using the delta-rs library.

Max Foxley-Marrable
Max Foxley-Marrable is an Analytics Engineer at Revolution Data Platforms with over eight years of experience spanning data engineering, machine learning, and cloud infrastructure. He specializes in building scalable, automated pipelines and data lakehouse solutions using tools like Python, Apache Spark, Azure, and Databricks. Known for his ability to demystify complex data problems, Max brings a strong research background and a passion for practical innovation.
Before joining RDP, Max earned a PhD in Astronomy and Astrophysics and led impactful research initiatives in both health data and geospatial analytics. He is a certified Microsoft and Databricks data professional and continues to explore ways to blend advanced analytics with real-world business needs.

