
TL;DR:
This article explores building a robust data lakehouse using the medallion architecture, which organizes data into three layers—Bronze for raw data ingestion, Silver for data transformation, and Gold for optimized data aggregation. Best practices for each layer are outlined, including creating a separate staging area for raw data in the Bronze layer, enforcing data quality checks in the Silver layer, and optimizing query performance in the Gold layer. By following these best practices, organizations can effectively manage data across the data lakehouse, ensuring structured, governed, and optimized data operations.

Introduction
The data landscape has undergone significant transformation in recent years, with the data lake emerging as a significant evolution beyond the traditional data warehouse. Designed to offer unprecedented flexibility and scalability, data lakes promised to liberate data engineers from the confines of rigid data warehouses, paving the way for more dynamic data handling and analytics.
However, the reality of managing data lakes often fell short of this ideal. Far from being clear and navigable bodies of water, many data lakes instead morphed into data swamps - dumping grounds of unstructured, siloed data, that ultimately became difficult to maintain, govern, and extract meaningful insights from. This lack of structure and governance often led to serious issues with data quality, data discovery, and ultimately, a loss of trust amongst downstream stakeholders.
The data lakehouse emerged as a direct response to these challenges, presenting a structured and governed approach that merged the best aspects of data lakes with data warehouses. This hybrid model has the flexibility to support both structured and unstructured data, whilst simultaneously supporting schema enforcement/evolution and ACID (Atomicity, Consistency, Isolation, Durability) transactions1 - enabling reliable data operations. To data lakehouse has quickly gained traction, with organisations recognizing its potential to revolutionize data management with a balanced, efficient approach.
The medallion (or multi-hop) architecture presents a methodical, multilayered approach to leveraging the data lakehouse’s true capabilities, enabling the seamless flow of data across the data lakehouse. This article will explore the medallion architecture in detail, and outline best practices for each layer of the architecture. Throughout this article, we are going to be assuming that we will be working with a cloud-based data lakehouse, and that we will by using Delta Lake as our storage layer. We will also be assuming that we are using Apache Spark as our processing engine. However, the principles outlined in this article can be applied to any data lakehouse, regardless of the specific technologies used.
Understanding the Medallion Architecture
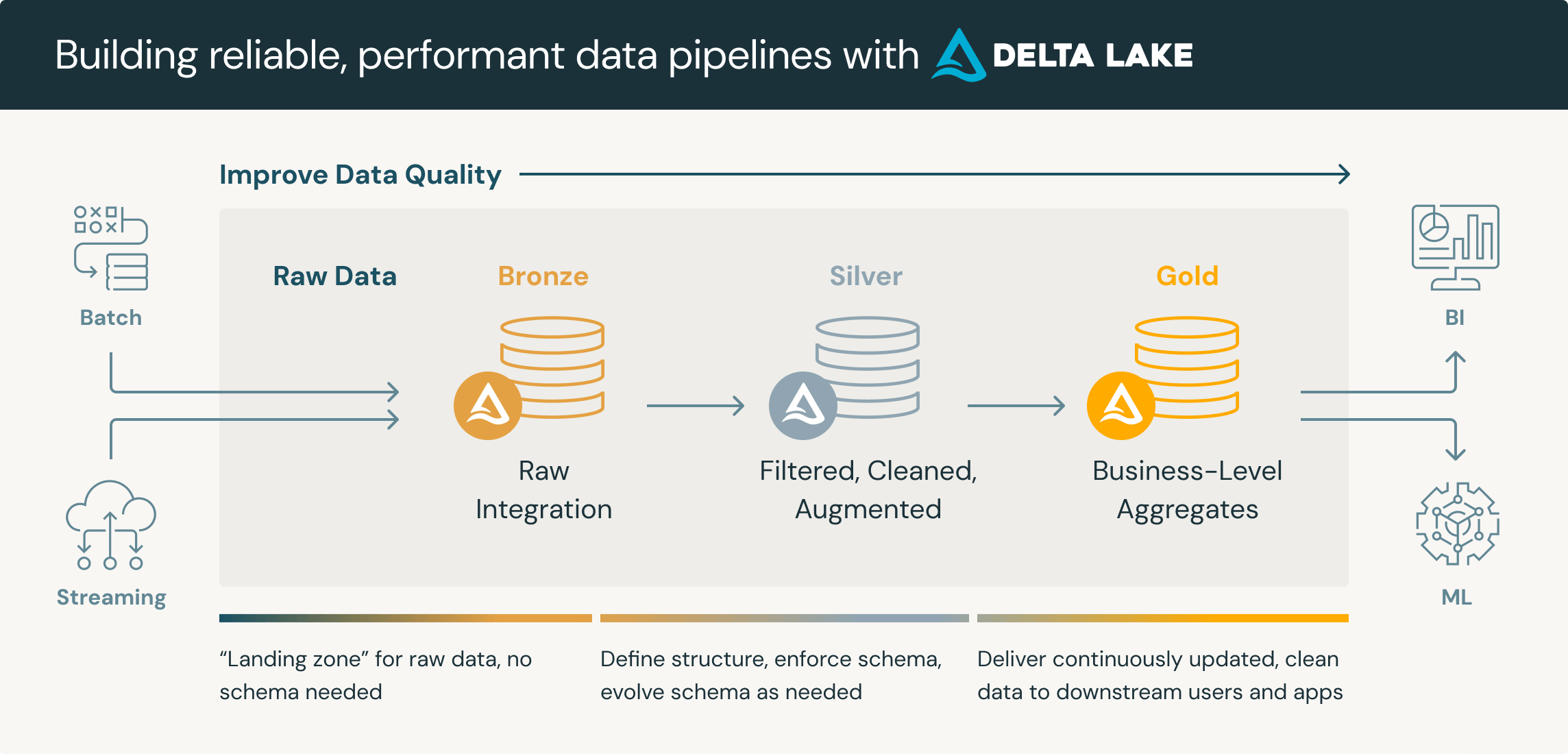 Source: Databricks: What is a medallion architecture? (https://www.databricks.com/glossary/medallion-architecture)
Source: Databricks: What is a medallion architecture? (https://www.databricks.com/glossary/medallion-architecture)
The medallion architecture breaks down the ingestion, transformation and serving of data into 3 distinct layers, each serving a specific purpose. These layers are interconnected, forming a multi-hop architecture that enables data to flow seamlessly across the data lakehouse. The medallion architecture comprises the following layers:
-
Bronze Layer: The bronze layer is where the raw data is ingested and often converted into a unified, storage-efficient format - namely Delta. Delta is a variation of the Parquet file format that includes transaction logs, enabling ACID transactions, basic CRUD (Create, Read, Update, Delete) operations, and schema enforcement. Like Parquet, Delta is an open-source columnar storage format that is optimized for querying and analytics. Additionally, being open-source means that Delta is compatible with a wide range of tools and platforms, preventing vendor lock-in.
-
Silver Layer: The silver layer is where the data is enriched and transformed, getting it ready for consumption downstream. Typical operations include data cleaning, deduplication, the creation of derived fields and the joining of tables to create new tables entirely. The silver layer is designed to ensure that the data is accurate, consistent, and reliable, making it suitable for use in analytics and reporting.
-
Gold Layer: The gold layer is the final layer in the medallion architecture, where the data is presented for consumption by downstream stakeholders. This layer typically involves aggregating data, creating summary tables, and optimizing the data for specific use cases. The gold layer is designed to ensure that the data is performant and efficient, making it suitable for use in production applications and real-time analytics.
Best Practices for Each Layer of the Medallion Architecture
The following section outlines three best practices for each layer - this is based on my experience and research, and is by no means exhaustive. This article should not be your only reference - gaining multiple perspectives is really important! Also be cognizant of the fact that the best practices for each layer can vary depending on the specific use case and requirements of your organization. Sometimes, trade-offs are required: layers may become interconnected, you may need to skip a layer/add new layers entirely, and so on. If you have to deviate too far from this blueprint, then maybe consider an alternative architecture that is better for your needs. Regardless, the following should provide a solid foundation for effectively implementing the medallion architecture in your data lakehouse.
Bronze Layer Best Practices
1. Consider creating a separate staging area for raw data
Creating a separate staging area for unprocessed raw data, distinct from the bronze layer, provides numerous benefits, most notably ensuring access to a pristine copy of raw data for debugging and reprocessing. This is crucial in the event of system failures, allowing data reprocessing without reverting to source systems - a vital feature during potential catastrophes. Whilst some view that the bronze layer should consist solely of unmodified raw data, I advocate for a separate raw layer to prevent the bronze layer from becoming a mere dumping ground for unformatted data, thereby not leveraging the full capabilities of a data lakehouse architecture, like time travel for data versioning if converting to delta format. Regardless of the approach to the bronze layer, a staging area remains beneficial, especially with a policy to truncate or archive its contents after a specified period to balance operational efficiency and storage costs.
2. Keep the data as is and preserve a full history if possible
The bronze layer should focus on preserving as much raw data as possible. Sometimes, some transformations are necessary on the raw data itself in order to make it readable by your processing framework and writable in your unified format. For example, you may have a CSV file that contains erroneous commas, or your source file contains illegal characters that are not supported by your unified format. Here, having the staging layer comes in handy, in case your transformations go awry and you need to reprocess the raw data. Overall, the goal should be to keep the bronze tables as close to the raw data as possible, and to perform the bulk of your transformations in the silver layer. Finally, storage is cheap. If possible, your bronze layer should ideally be append-only whilst keeping track of ingestion timestamps, meaning that you should never modify records in your bronze tables. This is because the raw data is the source of truth, and you should always be able to trace back to the original/older data in case of any issues. This is especially important in regulated industries where you need to maintain a full audit trail of your data.
3. Make your bronze schemas flexible or even ‘schemaless’
If using delta tables in your bronze layer, they should at least be designed to handle schema evolution. This means that your tables should be able to handle new fields being added, removed, or having their datatypes modified. This can be achieved by using a schema-on-read approach, and allowing your bronze tables to merge schema on write. This is especially important as upstream systems are prone to sudden and unexpected changes with your raw data. Alternatively, it is common for bronze tables contain the unparsed raw data in a text column, with other columns containing file metadata, leaving it to the silver layer to parse and transform the data into a structured format. This is especially useful if you have a large number of raw data files with varying (or even very similar) schemas, and you want to avoid having cluttering your bronze layer with an unmanageable number of tables - instead placing all raw data from a source system into a single multiplex table.
Silver Layer Best Practices
1. Quarantine bad data and enforce data quality checks
The silver layer is where you should focus on data quality and consistency. This means that you should have a robust data quality framework in place to identify and quarantine bad data, such as missing data, duplicates, outliers, and errors. Simply removing bad data can lead to data loss, which can be catastrophic for your downstream stakeholders. Instead, you should quarantine the bad data in a separate table, and use it to troubleshoot the root of the issue. Additionally, you should have a process in place to notify the relevant stakeholders of any data quality issues, and provide them with the necessary information to take corrective action. This can help you build trust with your stakeholders, and ensure that they have confidence in the data that you provide.
2. Ensure efficient transformations without sacrificing maintainability
The silver layer has the potential of becoming a major bottleneck in your data pipeline, especially if you have large volumes of data. It is important to ensure that your transformations are efficient and scalable. Avoid excessive table joins and apply filters as early as possible to minimize overhead. Also, consider writing your Spark transformations in SQL where possible, especially for simple operations. SQL is a declarative language, meaning that you specify what you want to do, and the database engine figures out how to execute it in the most efficient way possible. If more complex operations (such as string manipulation) are required (which can lead to horribly messy SQL code), consider using a procedural language such as Python or Scala. Scala is the native language for Spark, and is generally the most efficient language for writing Spark code. However, Python is also supported, and is generally easier to write, read and maintain. In general, I personally prioritize readability and maintainability where possible, especially if performance gains are negligible. This is because time saved in development and debugging is often more valuable, especially during an emergency. However, this is a personal preference, and you should consider the specific requirements of your organization.
3. Data should be source-system aligned
This is also applicable to the bronze layer, but it is especially important in the silver layer. The data in the silver layer should be specifically aligned and easily traceable back to the source system. If you have multiple sources, you should ideally have a separate bronze/silver layer for each source, with any cross source-system joins happening in the gold layer. This way, if you have any issues with data from a specific data source, you can simply reprocess the data from that source without having to reprocess the entire silver layer, which can be costly.
Gold Layer Best Practices
1. Only include tables that are directly relevant to downstream stakeholders
Typically this includes aggregates, summary tables, materialized views, and so on. However, this ultimately needs to be a collaborative decision between the data engineering team and end-users - good communication is paramount for effective data engineering solutions. If you end up including everything only you or your team think might be useful, you will likely end up with a bloated gold layer that is difficult to maintain and understand. This is especially important if you have a large number of tables in your silver layer, and you want to avoid overwhelming your downstream stakeholders. This will also defeat the principle of the gold layer being performant and efficient, as it will be difficult to optimize a large number of tables for specific use cases. So treat your gold layer as a curated collection of tables that are specifically designed to meet the needs of the business. If analysts or data scientists wish to access tables that are only occasionally relevant, e.g. for ad-hoc reporting, they could possibly query this data directly from silver layer instead - if that is agreeable with your security model.
2. Optimize for maximum query performance
Tables in the gold layer are likely going to be accessed more frequently than any other layer. To reduce time and cost, you should first ensure that the queries themselves are written as optimally as possible - within reason. Secondly, ensure that the gold tables themselves are optimized for query performance. For example, partitioning your tables can significantly reduce the amount of data that needs to be scanned when a query is executed. However, it is possible to over-partition, leading to small size partitions that dramatically reduce performance overall - so ensure that your partition sizes are practical with your data processing system. If working with delta format in particular, consider using the OPTIMIZE command to compact your potentially large number of small parque files into a smaller number of large ones. Use the VACUUM command to truncate historical time-travel data that is no longer relevant. Additionally, Z-Ordering can be used to optimize the performance of your queries by physically organizing the data in the table, reducing the amount of data that needs to be scanned. This principle is applicable to every layer in the medallion architecture, but is especially important in the gold layer as it affects the performance of your downstream stakeholders.
3. Ensure that the data is secure and well governed
This should apply to your entire data engineering solution, but is especially relevant in the gold layer. Apply the principle of least privilege to your data, ensuring that the data is only accessible by authorized users, and that the data is compliant with any relevant regulations. This is especially important if you are working with any sensitive data, such as personally identifiable information (PII) or financial data. For example, creating views that mask or hide sensitive data can be a good way to minimize security leaks within your organization. Additionally, you should ensure that the data is accurate, consistent, and reliable. This is especially important if the data is being used for analytics and reporting, as inaccurate or inconsistent data can lead to incorrect conclusions and decisions. As Warren Buffett once said “It takes 20 years to build a reputation and 5 minutes to ruin it. If you think about that, you’ll do things differently.”
Conclusion
The medallion architecture presents a methodical, multilayered approach to leveraging the data lakehouse’s true capabilities, enabling the seamless flow of data across the data lakehouse. Remember, the medallion architecture is not a one-size-fits-all solution - you may need to adapt it to suit the specific requirements of your organization. So make sure to communicate with your team and stakeholders, and be prepared to make adjustments as needed. Regardless, by considering the best practices outlined in this article, you can ensure that your data lakehouse is better structured, governed, and optimized for maximum efficiency and performance. This will ultimately enable your organization to extract meaningful insights from your data, and make informed decisions that drive business growth and success.
Further Reading/References
- What is a medallion architecture?
- Medallion Architecture: What is it?
- Medallion architecture: best practices for managing Bronze, Silver and Gold
- 6 Guiding Principles to Build an Effective Data Lakehouse
- Databricks Delta Lake Documentation
- Delta Lake: Up & Running
- The Fundamentals of Data Engineering
- Databricks Certified Data Engineer Associate - Preparation
- Databricks Certified Data Engineer Professional - Preparation
-
It is worth noting that ACID support in Delta Lake only guaranteed for transactions that act upon a single Delta table. Transactions that span multiple Delta tables do not guarantee ACID properties. ↩