
SPARK IS MUCH CHEAPER AND FASTER TO EXECUTE THAN DATAFLOWS!
I’m going to tell you why in this blog.
Microsoft Fabric offers a powerful unified analytics platform where you can leverage various engines to design your data pipelines. Two popular choices are Dataflows a low–code, visually driven approach and Spark notebooks, a code–centric, flexible environment for advanced analytics. Based on recent hands–on testing and thorough review of available documentation, if you’re looking for a data processing engine in Microsoft Fabric that doesn’t compromise on speed, efficiency, or control, read on. Recent hands–on tests and the latest Fabric documentation reveal that Spark Notebooks are not just an alternative, they’re a game changer.
The Spark Notebooks Advantages
- Tailor every step: Optimize partitioning, caching, and error handling to suit
your specific needs. - Integrate advanced analytics: Seamlessly embed machine learning models or statistical analyses that go beyond basic transformations.
- Debug interactively: Utilize real–time execution and detailed logs to rapidly pinpoint and fix issues.
Microsoft Fabric uses a capacity–based pricing model with SKUs like F2, F4, F8, and beyond. These tiers represent specific Compute Units (CUs) that you’re billed for based on consumption.
Capacity units (CUs) are units of measure that represent a pool of compute power needed. Compute power is required to run queries, jobs, or tasks.

CU Consumption
Example: F2 Capacity has 2 CU per 1 second = 2 CUs
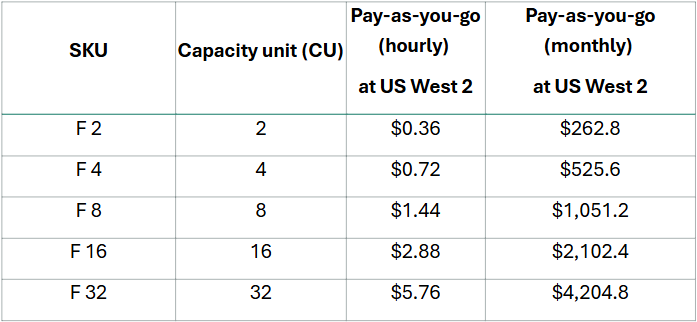
A Real Cost & Performance Comparison on an F4 Capacity
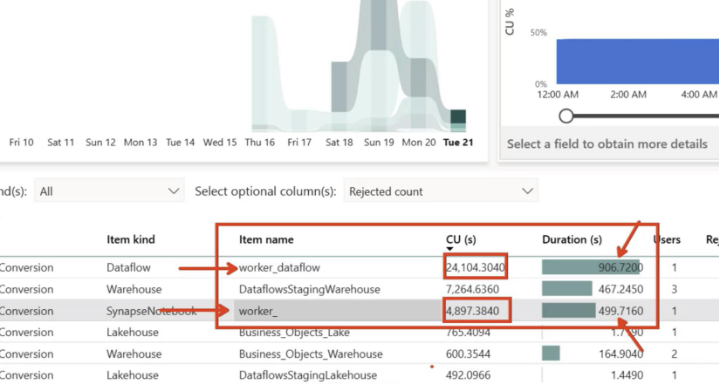
Scalability & transparency
Notebooks offer:
- Granular resource management: Monitor each step of your process and adjust settings in real–time.
- Better scaling: Whether you’re processing 10 GB or 1 TB, Spark Notebooks allow you to dynamically scale your code for peak performance.
- Clear cost tracking: Directly link optimizations to cost savings, giving you a transparent view of your budget versus performance.
The Bottom Line
For simple, routine ETL tasks, Dataflows might get the job done with minimal fuss. However, if your data projects demand complexity, customization, and a keen eye on performance and cost efficiency, Spark Notebooks are the clear winner in Microsoft Fabric.
- Complex transformations? Spark Notebooks let you handle them with precision.
- Optimized resource usage? Fine–tune your code to minimize Compute Unit consumption and save money.
- Rapid scalability and clear insights? Monitor and adjust in real–time, ensuring your pipeline is always performing at its best.
In today’s fast–paced data landscape, settling for a one–size–fits–all solution is not an option. Spark Notebooks provide the versatility, speed, and cost–effectiveness that modern data projects demand. If you’re serious about extracting every ounce of performance from Microsoft Fabric, it’s time to embrace the power of Spark Notebooks.
Happy Data Engineering! may your pipelines be fast, your costs low, and your insights sharp!

Mohamed Gamal
Mohamed Gamal is an experienced data engineer with over 3 years of expertise spanning data engineering, machine learning, and BI across several industries such as Finance, manufacturing, and technology. With a background in Computer Science and Engineering, he brings full-stack proficiency to the entire data lifecycle—
designing scalable data infrastructures, building distributed computing systems. He is also a Microsoft Certified: Fabric Analytics Engineer Associate, Gamal combines his technical depth and practical experience to solve complex data challenges and deliver end-to-end solutions that drive business value.